Unlock remote AI power with ngrok: A game-changer for developers

Your CTO has finally asked the question you, as a developer, have been afraid of and eagerly awaiting: “Can you, pretty please, validate how we could train and host a custom AI model for our product?”
Then they add a few caveats: “Can you host it in the cloud we already have? Make it secure? Make it collaborative, but also something you could convert into an API for in-product usage? And, if you don’t mind, could you not blow through our budget… again?”
Today, we’re going to extend some of the inspirational work the ngrok community and customers have done to train and develop on top of large language models (LLMs) faster and more securely using the ngrok agent and Cloud Edge. You’ll walk away with a solid proof of concept system for a workflow with good developer ergonomics and all the heavy compute AI requires.
It might not solve all your CTO’s questions, but it’ll be a solid start in the right direction.
Why connect your AI development to external CPU/GPU compute
The obvious first choice is to develop your LLM locally, as you do with other development work, committing changes and pushing them to a Git provider like GitHub.
The ecosystem is already rich with tools like LM Studio for this exact purpose. Rodrigo Rocco, for example, pleasantly surprised us when he showcased on Twitter/X how he’s running AI models locally and making results available externally through an ngrok tunnel. That said, there are limitations to the local-first model.
First, the most powerful LLMs require 16GB, 32GB, or even more RAM, plus a discrete GPU for churning through LLM-specific workloads. Your local workstation might not be that powerful now, and improvements aren’t in the budget. Or, even if you have a newer system, you don’t feel like taxing it, potentially slowing down other work, while you fine-tune a large language model (LLM) locally.
There are other limitations around collaboration and eventual hosting. A local development workflow doesn’t allow others to collaborate with you easily unless you expose your workstation to the public internet and leave it on 24/7. The same goes for the eventual transition into an API—better to build on a platform you won’t have to migrate off of inevitably.
When looking specifically at remote compute for LLM development, you have two choices:
- Hosted: Hosted platforms work like a SaaS—they launch your LLM on their infrastructure, and you get a simple web app or API to explore. There are plenty of hosted AI/LLM platforms already, like RunPod, Mystic, BentoML, and others. Major cloud providers also have platforms for training and deploying LLMs, like Google’s Vertex AI or AWS’ AI Services. Hosted platforms win out on simplicity but don’t come with privacy and compliance guarantees, and trend on the expensive side.
- Self-hosted: When you self-host an LLM, you install and configure the AI toolkit yourself on a barebones virtual machine (VM). There are LLM “orchestrator” tools, like Trainy, that claim to simplify the process, but also come with adoption learning curves. Self-hosting is typically cheaper in the long-term, but the onus is on you to build a workable AI development stack.
Hosted options are great for fast-moving startups that need to launch and train LLMs with the absolute minimum infrastructure, but you need something that’s both owned by your organization and persistent for continuous development.
Self-hosting is the best choice for this situation, but comes with new technical challenges.
Securely connecting your local workstation to a remote service requires you to deal with proxies, port forwarding, firewalls, and so on. If you were to bring an LLM service into production using the normal route—making a formal request with your DevOps peers—it might take weeks of code and coordination to get it running for security and compliance.
That said, companies like Softwrd.ai and Factors.ai are already using ngrok to connect to remote CPU/GPU compute, getting new AI-based APIs to market fast, which means you’re not the first to venture into this proof of concept using a powerful solution: ngrok.
Plan your tech stack for external AI compute
You’ve gone through all the technical requirements of building this proof of concept AI workflow—time for everyone’s favorite part of building new tech: deciding on your stack.
Based on the CTO’s goals and the roadblocks you’ve already found, a viable option consists of:
- A Linux virtual machine with GPU acceleration: You need a persistent, configurable machine for storing your LLM and computing responses. Because the next two parts of our stack run wherever Linux does, you can launch this VM wherever in whichever cloud provider works best for your organization. The only requirements are that your VM is GPU-accelerated and lets you install both Ollama and ngrok.
- Docker: The ubiquitous container toolkit, which you’ll use to run both Ollama and its web UI.
- Ollama: Ollama is an open source project that simplifies how developers run, interact with, and train LLMs. Its original purpose is to be run locally, but because it operates anywhere Linux does, and doesn’t require a web interface, it’s quite easy to install anywhere.
- ollama-webui: An open source, ChatGPT-style web client for an Ollama server. You’ll use this to interact with one or many LLMs, which is particularly useful as you validate which open source LLM will best suit your use case. The web UI also has basic Reinforcement Learning from Human Feedback (RLHF) and advanced parameters for tailoring conversations.
- ngrok: You’ll lean on ngrok’s universal ingress platform for securing and persisting ingress to Ollama and the web UI. ngrok abstracts away the networking and configuration complexities around securely connecting to remote services, while also layering in authentication, authorization, and observability you’ll need for a viable long-term solution.
This stack doesn’t come with official support from ngrok, and is by no means the only way of connecting your local development workflows to remote compute power. We’ve chosen it here due to its simplicity to get started:
- You can start playing with many popular open source LLMs in about 15 minutes.
- You can maintain your VM’s lifecycle through the GCP console, allowing you to stop your VM while it’s not in use to conserve that pesky budget when you’re not actively developing AI.
- Unlike hosted platforms, you own the node and its data.
- Unlike lower-cost platforms like Colab Pro, this solution is persistent, allowing you to store data and fine-tune an existing model in the future (see the following disadvantages).
There are some disadvantages to this approach, too:
- You’ll likely need to harden your VM, from a Linux and networking standpoint, against cyberattack… I’m sure your IT/DevOps peers would be thrilled to help.
- It requires more setup and maintenance than a purely hosted solution.
- On-premises hardware would likely be cheaper in the long-term.
- This stack currently lets you deploy existing open source models and customize certain parameters, but not perform deep re-training or fine-tuning.
Launch your remote Linux VM
Head on over to the Google Cloud Console and Create a VM.
Under Machine configuration, select GPUs and pick the GPU type that works for your budget and needs. For the machine type, pick a high memory instance, like n1-highmem-2. Down in the Boot disk section, click Switch Image to get an optimized operating system like Deep Learning on Linux, and up the size of the disk to 100 GB to be on the safe side. Down in the Firewall section, click Allow HTTPS traffic—ngrok will use that later to make your LLM accessible from anywhere.
That should be the fundamentals you need to launch remote AI compute—at about $0.35 per hour.
Give your instance some time to fire up. When it’s ready, SSH into it with your preferred method. The first time you log in, your VM will prompt if you want to install Nvidia drivers—hit <code>y</code> and <code>Enter</code>, as the reason you’re paying extra for VM is access to GPU compute.
Once that’s done, you can run <code>nvidia-smi</code> to verify that your GPU acceleration works as expected.
Install Ollama and the web UI via Docker
If your VM doesn’t already have Docker installed, follow the instructions in their documentation. You can then use <code>docker compose</code> to launch both Ollama and the ollama-webui project, with GPU acceleration enabled, with a single command:
Behind the scenes, the containers start an Ollama service on port <code>11434</code> and the web UI on port <code>3000</code>.
Install and start ngrok
To download the ngrok agent, head on over to the downloads page or quickstart doc for multiple options compatible with any Linux VM, Debian and beyond. Make sure you grab your Authtoken from your ngrok dashboard and connect your account.
While you have the ngrok dashboard open, create a new ngrok domain—this is your only method of having a consistent tunnel URL for all your future LLM training operations using this stack, either using a subdomain of <code>ngrok.app</code> or a custom domain you own. Replace the example domain in the below snippet before you run it.
The ngrok agent immediately starts forwarding any traffic on <code>https://NGROK_DOMAIN.ngrok.app:3000</code> to the Ollama web UI. Open your domain in your browser for a login prompt, but instead, click Sign in to create your administrator account, at which point you’ll be dropped into a ChatGPT-like interface for making your first requests.
Run your first LLM requests
The Ollama web UI provides a ChatGPT-like interface for interacting with many open source LLMs available in the Ollama library.
First, you need to pull the model(s) you want to work with. Click the ⚙️ near the top of the UI to open the settings, then Models, and type <code>llama2</code> into the textarea. Click the green button with the download icon to pull it. On the main UI, click Select a model->llama2:latest, and set it as the default if you’d like.
Time to send your remote LLM a message, request, or question, like this fundamental one: How do I hard boil eggs?
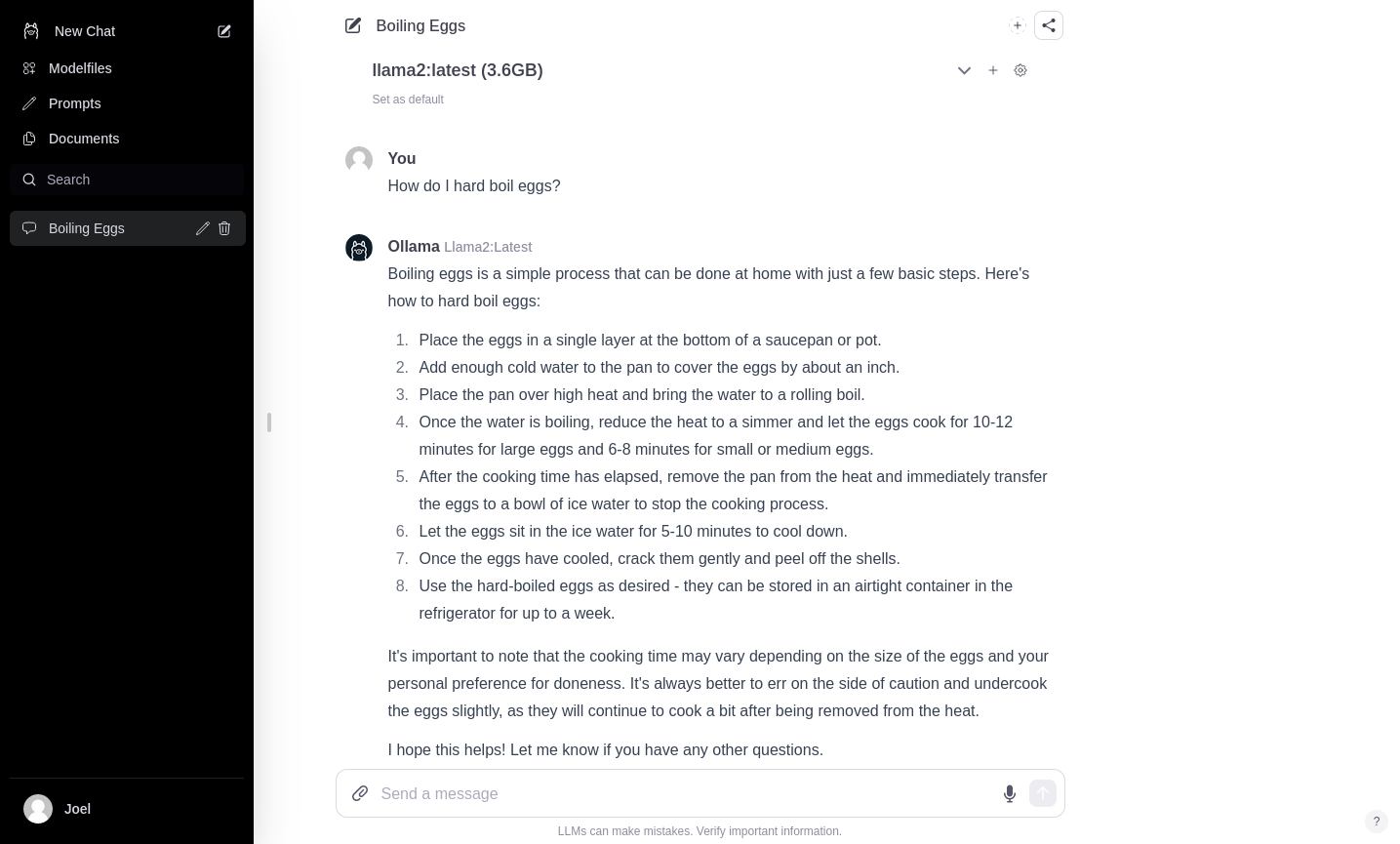
This is perfect for those who can’t remember whether you boil the water first then put the eggs in or boil them together... like myself. And with a high-memory, GPU-accelerated VM doing the hard work remotely, you should have gotten your answer within seconds—highly competitive with the closed-source, mysterious, and expensive alternatives like ChatGPT.
Optimize your ngrok-powered AI development with security and persistence
One of ngrok’s best features is how easily you can layer security features, like OAuth-based authentication, with CLI flags rather than trying to roll new infrastructure. The benefit of OAuth is that you can quickly restrict access to Ollama to only those with a GitHub account registered with an email address that matches your organization's domain name.
Append <code>--oauth=github --oauth-allow-domain YOUR_DOMAIN.TLD</code> to the previous command, adding the domain name you use for your GitHub account (or a different supported OAuth provider).
The next time you load the Ollama web UI after starting up your ngrok tunnel again, you’ll be asked to authenticate with your existing GitHub account.
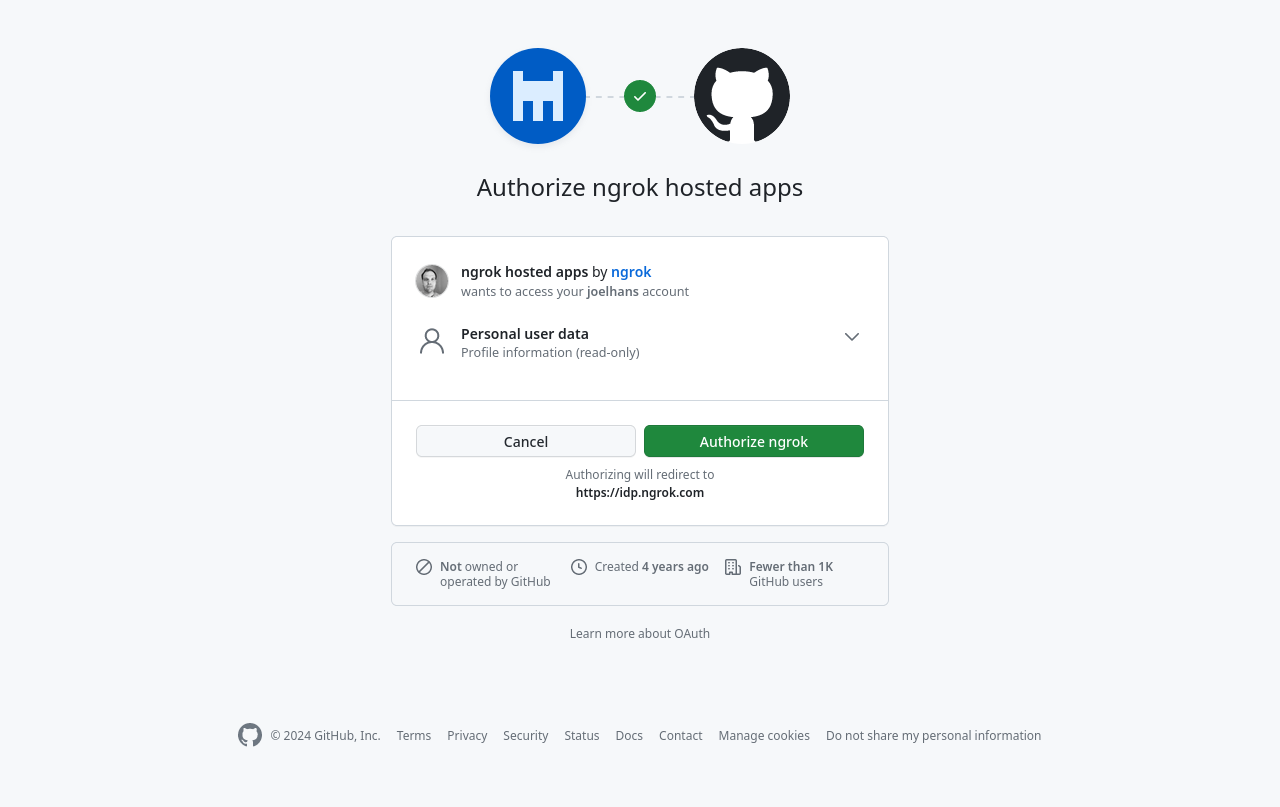
Once authorized with OAuth, the Ollama web UI will ask you to log in or sign up again. Admittedly, this is an imperfect solution—ideally, the OAuth handshake then registers a new account with those credentials—but the web UI currently doesn’t support that user flow. That said, it’s on their roadmap for future development.
Persistence helps if you use this remote LLM often or have others collaborate on it with you. You can run your ngrok tunnel as a background service by adding <code>> /dev/null &</code> to the end of your existing command.
What’s next?
With your LLM(s) self-hosted on a remote, GPU-accelerated VM, the sky’s the limit for you and your colleagues to test, tweak, and validate how to bring AI development more officially into your organization. You can explore the vast and fast-moving world of open source LLMs securely, collaboratively, and with complete control of your spending.
There are plenty of exciting paths to extend what you’ve already built:
- Use ngrok to ingress external requests directly to the Ollama API, delivering responses from your self-hosted LLM directly into your product.
- Explore Ollama’s model files, which allow you to customize a model with temperature (the spectrum between creative<->coherent) or its behavior (acting as Mario of the eponymous video game franchise).
- Learn how to fine-tune existing open source models on Hugging Face or with a framework like Axolotl. The developers behind Ollama are actively looking into adding fine-tuning support directly into Ollama, but for now, you can fine-tune a model elsewhere and upload the resulting GGUF file directly into the Ollama web UI to interact with it.
We'd love to know what you loved learning from this project by pinging us on X (aka Twitter) @ngrokhq, LinkedIn, or by joining our community on Slack.
